






Estimated Reading Time: 30-35 minutes (6,171 words)
Introduction
For decades, artificial intelligence was measured by one core question:
How intelligent is the model?
But in 2025 and beyond, a far more important question defines success:
How fast can intelligence be delivered—at scale, at low cost, and in real time?
Today’s digital economy runs on instant gratification. Users expect:
- Search answers in milliseconds
- Voice assistants that respond naturally, without lag
- Payments, fraud checks, and recommendations in real time
- AI copilots that assist while work is happening—not after
In this environment, latency has become the biggest bottleneck in AI adoption.
Even the most powerful AI model loses value if it takes too long to respond, costs too much to run, or cannot scale to millions of users simultaneously. This is why the global AI race is no longer just about bigger models—but faster, more efficient intelligence.
⚡ From “Smarter AI” to “Faster AI”
The industry is undergoing a fundamental shift:
- Early AI era: Accuracy and reasoning depth mattered most
- Current AI era: Speed, cost-efficiency, and real-time performance matter more
Modern AI use cases—such as live customer support, instant credit decisions, real-time translations, AI agents, and voice interfaces—cannot afford delays. A response that arrives one second late may already be irrelevant.
This shift has given rise to a new category of models known as frontier intelligence built for speed—AI systems engineered not just to think well, but to think fast.
🚀 Enter Gemini 3 Flash
This is exactly where Gemini 3 Flash comes in.
Developed by Google, Gemini 3 Flash is a frontier-level AI model purpose-built for high-speed, low-latency intelligence. Instead of maximizing raw reasoning at any cost, it focuses on:
- ⚡ Ultra-fast response times
- 💰 Lower inference and deployment costs
- 📈 Massive scalability for real-world applications
- 🧠 Sufficient intelligence for most everyday and business tasks
In simple terms, Gemini 3 Flash is designed for AI that needs to operate continuously, instantly, and affordably—whether it’s powering search, chatbots, AI agents, mobile apps, or enterprise workflows.
It’s not just about how smart AI is anymore—it’s about how quickly that intelligence can be delivered to millions of users.
🇮🇳 Why Speed-First AI Is Critical for India
Nowhere is this shift more important than India.
India’s digital ecosystem is defined by:
- 1.4+ billion people
- Mobile-first internet access
- Highly price-sensitive users
- Massive transaction volumes (UPI, e-commerce, fintech)
- Growing demand for vernacular and voice-based AI
In such an environment, slow or expensive AI simply does not scale.
Fast, efficient models like Gemini 3 Flash enable:
- Real-time UPI fraud detection
- Instant customer support in multiple Indian languages
- Affordable AI-powered education tools
- Scalable AI solutions for startups and MSMEs
For India, speed-first AI is not a luxury—it is infrastructure.
🌍 A New Era Where Milliseconds Matter
As AI becomes embedded into everyday digital experiences, milliseconds now define user satisfaction, trust, and adoption.
Gemini 3 Flash represents this new era:
- An AI model built not just for labs, but for the real world
- Not just for intelligence, but for instant intelligence
- Not just for a few enterprises, but for global and India-scale deployment
In the sections ahead, we’ll explore how Gemini 3 Flash works, where it excels, real-world use cases, market impact, and how businesses and creators can leverage it for growth and monetization.
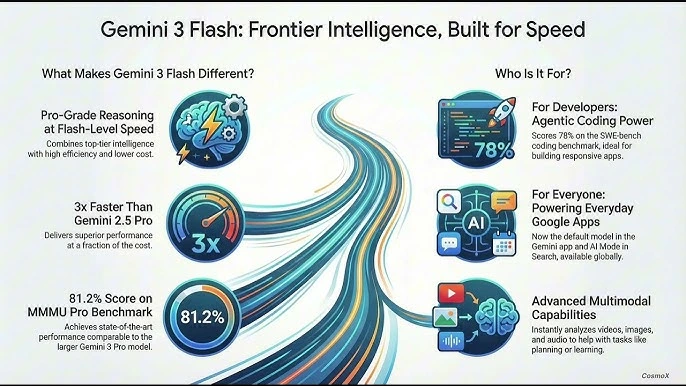
What Is Gemini 3 Flash?
Gemini 3 Flash is a next-generation, speed-optimized artificial intelligence model from Google’s Gemini family, specifically engineered to deliver high-performance intelligence with ultra-low latency and lower operational cost.
Rather than focusing solely on deep, resource-heavy reasoning, Gemini 3 Flash is designed for real-world, high-frequency AI usage—where responses must be instant, reliable, and scalable to millions of users simultaneously.
At its core, Gemini 3 Flash represents Google’s vision of frontier intelligence built for speed: an AI model that balances sufficient intelligence, fast inference, and economic efficiency, making it ideal for modern digital products.
⚡ Core Design Philosophy: Speed First, Intelligence Always
Traditional large AI models are often:
- Expensive to run
- Slow under heavy load
- Difficult to scale for consumer-facing applications
Gemini 3 Flash takes a different approach.
It is optimized to:
- Minimize response time (latency)
- Reduce compute and memory usage
- Maintain high accuracy for everyday tasks
- Operate continuously at internet scale
This makes it particularly suitable for applications where AI must respond in milliseconds, not seconds.
🔑 Key Characteristics of Gemini 3 Flash
⚡ Ultra-Fast Responses
Gemini 3 Flash is optimized for rapid inference, enabling near-instant replies for:
- Chat and conversational AI
- Search enhancements
- Voice assistants
- AI agents and workflows
This speed directly improves user experience, retention, and engagement—critical metrics for consumer apps and platforms.
💰 Lower Compute & Infrastructure Cost
One of the biggest advantages of Gemini 3 Flash is its cost efficiency.
By using optimized model architecture and inference strategies, Flash:
- Consumes less GPU/TPU compute per request
- Lowers per-token inference costs
- Enables affordable AI at scale
This is especially valuable for:
- Startups and MSMEs
- High-traffic platforms
- India’s cost-sensitive digital ecosystem
📱 Designed for Real-Time, High-Frequency AI Tasks
Gemini 3 Flash is built to handle:
- Millions of short, frequent AI requests
- Real-time decision-making
- Always-on AI services
Examples include:
- Instant customer support bots
- Live fraud detection systems
- Real-time content moderation
- Dynamic recommendations in e-commerce
Unlike heavyweight reasoning models, Flash thrives under continuous, high-volume workloads.
🌍 Massive-Scale Deployment Ready
Gemini 3 Flash is engineered to operate reliably at global internet scale.
It supports:
- Cloud-native deployment
- API-based integration
- Enterprise-grade reliability
- Seamless scaling across regions
This makes it suitable for:
- Consumer platforms (search, messaging, apps)
- Enterprise SaaS products
- Government and public digital infrastructure
⚖️ How Gemini 3 Flash Differs from Heavy Reasoning Models
While large reasoning models focus on:
- Deep logical reasoning
- Complex multi-step problem solving
- Long-form analysis
Gemini 3 Flash focuses on:
- Speed
- Responsiveness
- Cost efficiency
- Practical intelligence for everyday use
💡 Important Insight:
Gemini 3 Flash is not meant to replace advanced reasoning models—it complements them by handling fast, routine, and high-volume tasks, while heavier models are used only when deep reasoning is truly needed.
🧠 Built for the Modern AI Stack
Gemini 3 Flash fits naturally into today’s AI-driven architectures, including:
- AI copilots
- Autonomous agents
- Event-driven workflows
- Mobile and web applications
- Edge and cloud-based AI systems
Its flexibility allows developers and businesses to embed intelligence everywhere without performance penalties.
🧩 Simple Analogy: The AI Engine of the Internet Age
If heavyweight AI models are like supercomputers—powerful but expensive—then Gemini 3 Flash is like a high-performance engine:
- Always running
- Fuel-efficient
- Optimized for speed
- Built for mass adoption
Gemini 3 Flash is the AI engine for the internet age—fast, responsive, scalable, and always on.
🇮🇳 Why This Matters for India (Preview)
For India’s:
- Mobile-first population
- Massive transaction volumes
- Multilingual digital needs
- Startup-driven innovation ecosystem
Gemini 3 Flash enables AI at population scale, not just enterprise scale—unlocking new opportunities across fintech, education, e-commerce, and governance.
What Does “Frontier Intelligence Built for Speed” Mean?
The phrase “frontier intelligence built for speed” captures a fundamental shift in how modern AI systems are designed and evaluated.
In the past, AI innovation focused on building larger and more complex models. Today, the frontier has moved toward creating AI that delivers high-quality intelligence instantly, reliably, and at scale.
Gemini 3 Flash sits exactly at this intersection—frontier-level capability, engineered for real-world speed.
🔹 What Is “Frontier Intelligence”?
In AI research and industry, frontier models are those operating at the leading edge of capability and deployment. These models are not experimental prototypes; they are production-ready systems shaping how billions of people interact with technology.
Frontier intelligence typically includes:
🧠 Advanced Reasoning (Within Practical Limits)
- Strong contextual understanding
- High accuracy for common decision-making tasks
- Ability to follow instructions and workflows
- Reliable performance under real-world conditions
While not designed for extreme theoretical reasoning, frontier models like Gemini 3 Flash deliver “good-enough intelligence at massive scale”, which is often far more valuable commercially.
🖼 Multimodality
Modern frontier models can process and generate:
- Text
- Images
- Audio
- Video
Gemini 3 Flash supports multimodal inputs and outputs, enabling use cases such as:
- Image-based search
- Voice assistants
- Video understanding
- Document and form analysis
This multimodality allows AI to interact with the world the way humans do—across formats, not just text.
🌍 Scalability by Design
A key characteristic of frontier intelligence is global scalability.
Gemini 3 Flash is designed to:
- Serve millions of requests per second
- Operate reliably across regions
- Maintain performance during peak loads
This makes it suitable for:
- Consumer internet platforms
- High-traffic enterprise systems
- National-scale digital infrastructure
🧠 General Intelligence for Everyday Tasks
Rather than specializing in a narrow domain, frontier intelligence models provide broad, general-purpose capability, allowing them to:
- Answer questions
- Generate content
- Assist workflows
- Automate decisions
Gemini 3 Flash focuses on practical general intelligence—intelligence that works instantly across many tasks, rather than excelling only in rare, complex scenarios.
🔹 What Does “Built for Speed” Really Mean?
Speed-first AI is not just about faster hardware—it’s about end-to-end optimization across the entire model lifecycle.
Gemini 3 Flash is engineered to minimize delay at every step.
⚡ Lower Latency per Token
Latency refers to the time taken for the model to generate each unit of output (token).
Lower latency means:
- Faster start of response
- Smoother conversational flow
- Better voice and chat experiences
In real-world applications, this can mean the difference between a natural interaction and a frustrating one.
🚀 Faster Inference at Scale
Inference is the process of generating outputs from a trained model.
Gemini 3 Flash is optimized to:
- Deliver responses quickly even under heavy load
- Handle large volumes of concurrent requests
- Maintain consistent performance during traffic spikes
This is critical for platforms serving millions of users simultaneously.
🧩 Optimized Model Architecture
Speed-first models use architectural optimizations such as:
- Efficient parameter utilization
- Streamlined attention mechanisms
- Reduced computational overhead
These design choices allow Gemini 3 Flash to deliver high-quality responses without unnecessary compute cost.
💾 Efficient Memory Usage
Memory efficiency directly impacts:
- Infrastructure cost
- Deployment flexibility
- Scalability
By using memory more efficiently, Gemini 3 Flash:
- Runs more requests per GPU/TPU
- Reduces cloud infrastructure expenses
- Enables wider adoption across startups and enterprises
📌 Why Speed-First Frontier Intelligence Matters in the Real World
In theory, intelligence quality is important. In practice, speed determines adoption.
Research consistently shows:
- Users abandon apps if responses take more than 2 seconds
- In conversational interfaces, even 500 ms delays feel noticeable
- Faster responses increase user trust and engagement
For real-time systems—such as:
- Search engines
- Voice assistants
- Payment verification
- Fraud detection
- AI agents
Instant intelligence is non-negotiable.
Gemini 3 Flash is engineered to operate within these tight performance constraints, making it suitable for real-world, revenue-generating applications rather than just demonstrations.
🇮🇳 Why This Matters Even More for India
India’s digital ecosystem magnifies the importance of speed:
- Mobile networks vary in quality
- Users are extremely price-sensitive
- Platforms must scale to hundreds of millions of users
- Real-time systems like UPI demand instant responses
Fast, efficient frontier models like Gemini 3 Flash make it possible to deliver high-quality AI experiences at population scale—without breaking cost or infrastructure limits.
🧠 In Simple Terms
Frontier intelligence built for speed means delivering powerful, general-purpose AI that responds instantly, scales globally, and remains affordable in real-world conditions.
That is exactly the problem Gemini 3 Flash is designed to solve.
Key Features of Gemini 3 Flash
Gemini 3 Flash is not just a faster AI model—it is a carefully engineered system designed for real-world, high-scale deployment. Every feature is optimized to deliver instant intelligence, cost efficiency, and reliable performance across consumer and enterprise environments.
Below are the core capabilities that define Gemini 3 Flash and explain why it is emerging as one of the most practical frontier AI models in production.
🚀 Core Capabilities of Gemini 3 Flash
⚡ Ultra-Low Latency Inference
At the heart of Gemini 3 Flash is its ability to respond almost instantly.
Ultra-low latency inference means:
- Faster time-to-first-token
- Smoother conversational flow
- Near real-time responses for voice, chat, and agent-based systems
This is critical for:
- AI chatbots and assistants
- Search enhancements
- Voice-based applications
- Live decision systems (fraud detection, alerts, recommendations)
💡 Impact: Faster responses increase user satisfaction, engagement, and trust—especially in consumer-facing apps.
🧠 Multimodal Input & Output (Text, Image, Audio, Video)
Gemini 3 Flash is built as a multimodal AI model, allowing it to understand and generate across multiple data formats:
- Text: Chat, search, summarization, translation
- Images: Visual recognition, image-based queries
- Audio: Voice input, transcription, speech understanding
- Video: Frame-level understanding, content analysis
This enables advanced use cases such as:
- Voice-enabled assistants
- Image-based search and support
- AI tutors using text + visuals
- Content moderation across media formats
📌 Why this matters: Real-world AI interactions are rarely text-only. Multimodality allows Gemini 3 Flash to function like a general-purpose digital brain.
💰 Cost-Efficient API Pricing
One of Gemini 3 Flash’s most important advantages is economic efficiency.
By optimizing model architecture and inference pipelines, Google enables:
- Lower per-request costs
- Reduced GPU/TPU consumption
- Better cost predictability at scale
This makes Gemini 3 Flash ideal for:
- Startups and MSMEs
- High-traffic consumer platforms
- Cost-sensitive markets like India
💡 Business Insight: Companies can deploy AI broadly—across customer support, operations, and automation—without unsustainable infrastructure expenses.
🌍 Scalable for Millions of Users
Gemini 3 Flash is designed from the ground up for massive scale.
It can:
- Handle millions of concurrent requests
- Maintain performance during traffic spikes
- Scale across regions and time zones
This makes it suitable for:
- Search engines and digital platforms
- E-commerce and fintech systems
- Public-facing government services
- Large SaaS products
📊 Key Advantage: Scalability ensures consistent AI performance whether you serve 1,000 users or 100 million.
🤖 Optimized for AI Agents & Automated Workflows
Modern AI is moving beyond chatbots toward autonomous agents and workflow automation.
Gemini 3 Flash is optimized for:
- Event-driven AI agents
- Multi-step automated workflows
- Real-time task execution
- Integration with APIs and business systems
Example agent use cases:
- AI customer support agents
- Automated sales follow-ups
- Fraud detection bots
- Operations and monitoring assistants
🚀 Why Flash works here: Agents require fast, frequent interactions—exactly what Gemini 3 Flash is built for.
📦 Key Facts Box: Gemini 3 Flash at a Glance
🔹 Designed for real-time applications
Ideal for use cases where instant responses are essential.
🔹 Optimized for search, chat, and automation
Supports high-volume conversational and decision-making workloads.
🔹 Ideal for mobile & cloud deployment
Runs efficiently in cloud environments and supports mobile-first experiences.
🔹 Supports enterprise-grade workloads
Reliable, scalable, and secure enough for business-critical systems.
🇮🇳 Why These Features Matter for India
India’s digital economy amplifies the importance of Gemini 3 Flash’s feature set:
- Massive user volumes demand scalability
- Mobile-first usage requires low latency
- Cost sensitivity makes efficiency critical
- Multilingual, multimodal interaction is essential
Gemini 3 Flash enables AI adoption at population scale, unlocking value for:
- Indian startups
- Fintech platforms
- EdTech and HealthTech apps
- Government digital initiatives
🧠 In Simple Terms
Gemini 3 Flash combines speed, intelligence, and affordability, making it one of the most practical frontier AI models for real-world deployment today.
It is not designed to impress in theory—it is designed to perform in production.
Gemini 3 Flash vs Traditional Large Reasoning Models
As artificial intelligence adoption matures, one critical realization has emerged:
Not all AI tasks require the same type of intelligence.
While traditional large reasoning models are powerful, they are not always practical for real-world, high-volume applications. Gemini 3 Flash takes a fundamentally different approach—prioritizing speed, efficiency, and scalability over maximum reasoning depth.
Understanding the differences between these two model categories helps businesses, developers, and creators choose the right AI for the right job.
📊 Feature-by-Feature Comparison
| Feature | Gemini 3 Flash | Traditional Large Reasoning Models |
| Speed | ⚡ Extremely fast responses, optimized for real-time usage | Medium to slow due to complex reasoning |
| Cost | 💰 Low per-request and scalable pricing | 💸 High compute and inference costs |
| Latency | ⏱ Ultra-low latency, near-instant replies | Higher latency, noticeable delays |
| Primary Strength | Real-time intelligence and automation | Deep reasoning and complex problem-solving |
| Scalability | 🌍 Massive, internet-scale deployment | ⚠️ Limited due to resource intensity |
| User Experience | Smooth, conversational, responsive | Often slower, batch-oriented |
| Best Fit Use Cases | Chatbots, search, agents, fintech, SaaS | Research, complex analysis, long reasoning |
| Infrastructure Needs | Optimized, cost-efficient | Heavy GPU/TPU requirements |
🧠 Speed vs Intelligence: A Practical Trade-Off
Traditional large reasoning models are designed to:
- Solve multi-step logical problems
- Perform deep analytical reasoning
- Handle complex, abstract tasks
However, these capabilities come with trade-offs:
- Higher latency
- Higher infrastructure cost
- Limited scalability
Gemini 3 Flash deliberately sacrifices unnecessary reasoning depth to deliver:
- Faster responses
- Lower cost
- Better user experience
- Scalable deployment
📌 Key Insight:
For most consumer and enterprise applications, fast and accurate responses are more valuable than perfect reasoning.
🚀 Real-World Example: Which Model Works Better?
Scenario 1: Customer Support Chatbot
- Needs instant replies
- Handles thousands of conversations simultaneously
- Cost-sensitive
✅ Best Choice: Gemini 3 Flash
Scenario 2: Financial Report Analysis
- Requires deep reasoning
- Multi-step analysis
- Low frequency usage
✅ Best Choice: Large reasoning model
Scenario 3: UPI Fraud Detection (India)
- Must operate in milliseconds
- Extremely high transaction volume
- Real-time decisions
✅ Best Choice: Gemini 3 Flash
🤖 Complementary, Not Competitive
A common misconception is that faster models will replace intelligent ones. In reality, modern AI systems use both.
Hybrid AI Architecture (Best Practice)
- Gemini 3 Flash handles:
- Real-time interactions
- User-facing tasks
- High-frequency decisions
- Real-time interactions
- Large reasoning models handle:
- Complex analysis
- Strategic decisions
- Edge-case reasoning
- Complex analysis
This hybrid approach:
- Reduces cost
- Improves performance
- Enhances reliability
💡 Industry Trend:
Enterprises increasingly deploy multiple AI models, each optimized for specific workloads.
🇮🇳 Why This Comparison Matters for India
India’s digital ecosystem amplifies the advantages of Gemini 3 Flash:
- Massive user base → scalability required
- Mobile-first internet → low latency critical
- Cost-sensitive market → affordable AI needed
- High transaction volume → real-time intelligence
Traditional large models are often too expensive and slow to deploy at India-scale.
Gemini 3 Flash enables:
- AI adoption by startups and MSMEs
- Nationwide AI-powered services
- Affordable AI for consumers
📌 Summary: Choosing the Right Model
| Use Case Type | Recommended Model |
| Real-time apps & chat | Gemini 3 Flash |
| AI agents & automation | Gemini 3 Flash |
| High-volume fintech systems | Gemini 3 Flash |
| Research & deep analysis | Large reasoning models |
| Strategic planning | Large reasoning models |
💡 Final Insight
Gemini 3 Flash doesn’t replace heavy reasoning models—it makes AI usable at real-world scale.
By combining speed, affordability, and sufficient intelligence, Gemini 3 Flash acts as the frontline AI, while traditional models operate as specialized intelligence layers behind the scenes.
Why Speed Matters in AI (Especially for India)
India is not just another AI market—it is a scale market.
With hundreds of millions of users coming online, conducting real-time digital transactions, and interacting primarily through mobile devices, speed is the foundation of usable AI in India. Any AI system that is slow, expensive, or bandwidth-heavy simply fails to scale in the Indian context.
This is why speed-first AI models like Gemini 3 Flash are critical for India’s digital future.
📱 India’s Digital Ecosystem Demands Speed
India’s AI requirements are shaped by four non-negotiable realities:
📡 Low & Variable Bandwidth Environments
Despite rapid 4G and 5G expansion, many users still operate on:
- Congested mobile networks
- Inconsistent connectivity
- Budget data plans
AI models must therefore:
- Respond quickly
- Transmit minimal data
- Deliver value even on slower networks
Fast inference reduces the time data stays in transit, improving reliability across regions.
💰 Affordable Compute at Massive Scale
India is one of the most price-sensitive digital markets in the world.
High-cost AI models:
- Increase operational expenses
- Make AI products unaffordable
- Limit adoption to large enterprises
Speed-optimized models like Gemini 3 Flash reduce:
- GPU/TPU usage
- Cloud infrastructure cost
- Per-user AI expense
📌 Result: AI becomes economically viable for startups, MSMEs, and public platforms.
⚡ Real-Time User Experience (UX)
Indian users are accustomed to:
- Instant UPI payments
- Real-time notifications
- Fast app interactions
Even slight delays in AI responses can:
- Break user trust
- Reduce engagement
- Increase churn
For applications like:
- Payments & fraud detection
- Customer support
- Voice assistants
- Live recommendations
Sub-second AI responses are mandatory, not optional.
🗣 Regional Language & Voice Support
India’s next billion internet users are:
- Vernacular-first
- Voice-driven
- Less text-centric
AI systems must:
- Process speech instantly
- Respond in local languages
- Handle high volumes of short interactions
Speed-first models ensure:
- Natural conversational flow
- Better voice recognition accuracy
- Lower latency in speech-to-text and responses
📊 India-Specific Drivers Accelerating Speed-First AI
📱 850+ Million Smartphone Users
India has one of the largest smartphone populations globally, creating:
- Massive concurrent AI usage
- Peak traffic bursts
- Always-on digital demand
AI systems must scale instantly without performance degradation.
💳 UPI Handles 10+ Billion Monthly Transactions
India’s UPI ecosystem processes billions of transactions every month, each requiring:
- Real-time verification
- Instant fraud detection
- Immediate confirmation
Even milliseconds matter.
Speed-first AI enables:
- Real-time anomaly detection
- Transaction risk scoring
- Automated customer support
🎙 Explosion of Voice & Vernacular AI Demand
From:
- Voice search
- IVR automation
- AI call centers
- Regional language assistants
India is rapidly moving toward voice-first AI interaction.
These use cases require:
- Fast speech processing
- Immediate AI responses
- Minimal delay to feel “human”
Gemini 3 Flash is well-suited for such high-frequency, short-turn interactions.
🚀 Rising AI Adoption Among SMEs & Startups
India’s startup ecosystem is increasingly AI-driven—but:
- Budgets are limited
- Infrastructure must scale fast
- AI must deliver ROI quickly
Speed-first, cost-efficient models allow startups to:
- Deploy AI earlier
- Experiment affordably
- Scale without massive cloud bills
🧠 Real-World Indian Use Cases Where Speed Is Critical
- UPI fraud detection systems
- AI customer support for telecom & banks
- E-commerce recommendations during sales
- EdTech doubt-solving apps
- HealthTech triage chatbots
- Government digital services
In each case, slow AI equals failed UX.
🌍 AI for Bharat, Not Just Big Tech
Traditional large AI models work well for:
- Research labs
- Premium enterprise solutions
- Low-frequency, high-value tasks
But India needs AI that:
- Works for millions
- Costs less per user
- Responds instantly
- Supports diversity and scale
Fast, efficient models like Gemini 3 Flash democratize AI, enabling:
- Small businesses
- Regional startups
- Public platforms
- Everyday users
Gemini 3 Flash unlocks AI for Bharat—not just for Big Tech.
📌 Key Takeaway
In India, speed is not a feature—it is the foundation.
AI models that are fast, affordable, and scalable will define the country’s digital future. Gemini 3 Flash is built precisely for this reality.
Real-World Use Cases of Gemini 3 Flash (Global + India)
Gemini 3 Flash is designed for practical, real-world deployment, not just experimental AI demos. Its speed-first architecture makes it ideal for industries where real-time responses, high volume, and cost efficiency matter most.
🧑💻 Consumer Apps
In consumer-facing applications, user patience is extremely low. Gemini 3 Flash enables smooth, instant interactions across:
- AI chat assistants: Fast, conversational responses improve engagement and retention in messaging apps and websites.
- Voice search: Near-instant processing enables natural, voice-first interactions—especially important for mobile users.
- Smart replies: Real-time suggestions in email, messaging, and social apps reduce user effort.
- Image recognition: Quick image understanding powers search, shopping, and content moderation features.
📌 Why Flash works here: Consumer apps require speed at scale, often serving millions of short, frequent requests.
🏦 Fintech & Banking (India Focus)
India’s fintech ecosystem processes billions of real-time transactions, making speed-critical AI essential.
Key use cases include:
- Fraud detection: Real-time anomaly detection during UPI and card transactions.
- Instant credit scoring: AI-driven decisions using alternative data without long wait times.
- KYC automation: Faster document and face verification improves onboarding.
- Real-time alerts: Immediate notifications build trust and prevent losses.
💡 Impact: Faster AI directly translates to higher security and better customer experience.
🛍 E-commerce
In e-commerce, milliseconds influence conversion rates.
Gemini 3 Flash supports:
- Personalized recommendations based on live browsing behavior
- Dynamic pricing adjusted in real time to demand and competition
- Customer support bots that handle high query volumes instantly
📈 Result: Faster responses → higher engagement → improved sales.
🎓 Education & Upskilling
EdTech platforms rely heavily on instant feedback and personalization.
Use cases include:
- AI tutors that respond immediately to student queries
- Instant doubt solving during live learning sessions
- Adaptive learning paths that adjust content in real time
For India’s massive student population, speed-first AI makes personalized education scalable and affordable.
Business & Developer Applications
Beyond consumer use cases, Gemini 3 Flash plays a crucial role in developer platforms and enterprise systems.
🔧 For Developers
Developers use Gemini 3 Flash to build:
- AI APIs for mobile and web apps with low latency
- AI agents & workflows for automation and task execution
- SaaS automation features embedded into products
- Real-time analytics and monitoring tools
Its speed allows developers to create responsive AI features without massive infrastructure costs.
🏢 For Enterprises
Enterprises deploy Gemini 3 Flash across:
- Customer support automation (chat, voice, ticket triage)
- Sales & CRM intelligence (lead scoring, follow-ups)
- Document processing (contracts, invoices, compliance)
- Internal knowledge bots for employees
📌 Benefit: Enterprises get faster decision-making at lower operational cost.
💡 Case Example (India)
Many Indian SaaS startups adopting speed-optimized AI models report:
- 40–60% reduction in cloud AI costs
- Higher throughput per server
- Improved customer response times
This enables startups to scale AI features earlier without burning capital.
Benchmarks & Performance Insights
While benchmarks vary by workload and deployment, speed-optimized frontier models like Gemini 3 Flash typically demonstrate:
- 2–3× faster inference compared to heavy reasoning models
- Lower cost per request, especially at high volumes
- Higher throughput per GPU/TPU, improving infrastructure efficiency
📌 Key Takeaway:
For high-volume, real-time AI usage, speed and efficiency outperform raw reasoning depth.
Market Trends & Adoption
📊 Global Trends
Globally, AI is shifting from static intelligence to active systems:
- AI models moving from “thinking” → “acting”
- Rapid rise of AI agents and automation
- Strong demand for real-time AI APIs in apps and platforms
Speed-first models are becoming the default layer for AI-powered products.
🇮🇳 India-Specific Trends
India’s AI adoption is accelerating due to:
- Growing AI usage among MSMEs and startups
- Government-backed digital and AI initiatives
- Rising demand for vernacular and voice-based AI
- Startup-led innovation focused on scale and affordability
Fast, cost-efficient AI models are central to this growth.
10-Year Outlook: AI & Speed (2025–2035)
| Year | Key Shift |
| 2025 | Speed-first AI becomes mainstream |
| 2030 | AI agents embedded across apps and businesses |
| 2035 | AI becomes invisible infrastructure in daily life |
📌 Prediction:
By 2035, fast, efficient AI models will power 80%+ of consumer-facing AI interactions, while heavy reasoning models operate mainly behind the scenes.
🧠 Final Insight for This Section
The future of AI does not belong to the biggest models—it belongs to the fastest usable intelligence at scale.
Gemini 3 Flash sits at the center of this shift.
Risks & Limitations of Gemini 3 Flash
While Gemini 3 Flash delivers exceptional speed and scalability, no AI model is without trade-offs. Understanding its limitations is critical for building reliable, ethical, and production-grade AI systems—especially at scale.
🧠 1. Limited Deep Reasoning Capability
Gemini 3 Flash is optimized for fast inference, not prolonged multi-step reasoning.
This means:
- It may struggle with complex logic chains
- Not ideal for advanced mathematical proofs
- Less effective for long-form strategic planning
- May oversimplify nuanced or ambiguous problems
📌 Best practice:
Use Flash for real-time responses, and route complex queries to heavier reasoning models when needed.
🎭 2. Risk of Hallucinations
Like most large language models, speed-optimized AI can occasionally:
- Generate confident but incorrect answers
- Infer missing facts instead of asking for clarification
- Misinterpret vague or poorly structured prompts
This risk increases in:
- Financial advice
- Medical or legal contexts
- Automated decision systems
📌 Mitigation strategies:
- Add fact-checking layers
- Use retrieval-augmented generation (RAG)
- Limit outputs to verified data sources
- Apply confidence scoring for sensitive tasks
🤖 3. Over-Automation & Human Dependency Risks
Ultra-fast AI models can encourage businesses to:
- Replace human oversight too aggressively
- Automate customer-facing decisions prematurely
- Reduce critical human-in-the-loop checks
Potential consequences include:
- Poor customer experiences
- Unfair or biased outcomes
- Loss of accountability in decision-making
📌 Solution:
Adopt human-in-the-loop workflows, especially in high-stakes domains like finance, hiring, healthcare, and governance.
⚖️ 4. Ethical AI & Governance Challenges
Speed and scale introduce new ethical risks:
- Bias amplification at high request volumes
- Misuse in spam, misinformation, or deepfake pipelines
- Lack of transparency in automated decisions
- Regulatory non-compliance across regions
In India and globally, AI regulations are evolving rapidly, making responsible deployment essential.
📌 Governance essentials:
- Clear AI usage policies
- Bias audits and model monitoring
- Explainability layers for decisions
- Compliance with local data protection laws
🔐 5. Security & Data Privacy Considerations
Fast AI models often handle real-time user data, raising concerns around:
- Data leakage
- Prompt injection attacks
- Insecure API integrations
- Over-logging sensitive information
📌 Security best practices:
- Strong access controls
- Encrypted data pipelines
- Prompt filtering and validation
- Minimal data retention policies
🔔 Pro Tip: Use a Hybrid AI Architecture
The smartest AI systems combine speed with safeguards.
To maximize value:
- Use Gemini 3 Flash for front-end, high-frequency tasks
- Pair it with verification, retrieval, and reasoning layers
- Maintain human oversight for critical decisions
This hybrid approach delivers speed, accuracy, and trust—the three pillars of production-grade AI.
FAQs Section
1. What is Gemini 3 Flash?
Gemini 3 Flash is a speed-optimized frontier AI model from Google’s Gemini family, purpose-built for real-time, high-volume intelligence tasks.
Unlike heavy reasoning models that prioritize depth over speed, Gemini 3 Flash focuses on:
- Ultra-low latency responses (milliseconds)
- Lower compute and inference costs
- Massive scalability for consumer and enterprise apps
- Seamless deployment across mobile, cloud, and APIs
It is designed to power search, chat, automation, AI agents, and real-time decision systems at internet scale.
2. What does “frontier intelligence built for speed” actually mean?
“Frontier intelligence” refers to state-of-the-art AI capabilities—including multimodality, reasoning, and general intelligence—while “built for speed” means the model is architected to deliver those capabilities with minimal latency.
In practice, this means:
- Faster inference per token
- Optimized memory and compute usage
- High throughput per GPU/TPU
- Minimal response delay for users
📌 This combination is critical for real-world products, where users expect instant AI responses, not delayed intelligence.
3. Is Gemini 3 Flash better than GPT models?
Gemini 3 Flash is not universally “better”, but better suited for specific use cases.
Compared to heavy GPT-style reasoning models:
- ✅ Faster response times
- ✅ Lower cost per request
- ✅ Better for real-time, high-frequency tasks
- ❌ Less capable at deep, multi-step reasoning
📌 Best approach:
Use Gemini 3 Flash for front-end, real-time interactions, and pair it with deeper reasoning models for complex tasks.
4. Is Gemini 3 Flash available in India?
Yes. Gemini 3 Flash is available in India through Google’s AI ecosystem, including:
- Cloud-based APIs
- Developer platforms
- Enterprise AI solutions
- Integration into Google products and services
India is a key market for speed-optimized AI due to:
- Mobile-first internet usage
- Cost sensitivity
- Massive scale (users + transactions)
Growing startup and MSME adoption
5. What are the best use cases for Gemini 3 Flash?
Gemini 3 Flash excels in real-time, high-volume applications, including:
- AI chatbots and virtual assistants
- Voice search and speech-to-text
- Smart replies and autocomplete
- Fraud detection and alerts
- Instant KYC and document verification
- AI agents and workflow automation
- Customer support and CRM intelligence
- Personalized recommendations in e-commerce
- Adaptive learning in edtech platforms
6. Is Gemini 3 Flash suitable for startups and MSMEs?
Yes—it’s one of the most startup-friendly AI models available.
Key advantages for startups:
- Lower API and infrastructure costs
- Faster time-to-market
- Scales from 1,000 to 1 million users seamlessly
- Ideal for MVPs, SaaS tools, and consumer apps
📌 Many Indian startups use speed-first models to cut AI cloud costs by 40–60% compared to heavy models.
7. Does Gemini 3 Flash support Indian and regional languages?
Yes. Gemini models support multilingual and vernacular AI capabilities, including major Indian languages such as:
- Hindi
- Tamil
- Telugu
- Kannada
- Marathi
- Bengali
- Gujarati and more
This makes Gemini 3 Flash highly suitable for:
- Voice assistants for Bharat
- Regional language chatbots
- Government and public service platforms
Rural and semi-urban digital adoption
8. Is Gemini 3 Flash safe for enterprise and regulated industries?
Yes, when deployed responsibly.
For enterprise use, organizations should:
- Add verification and validation layers
- Use retrieval-augmented generation (RAG)
- Implement human-in-the-loop workflows
- Follow AI governance and compliance standards
With these controls, Gemini 3 Flash can be safely used in:
- Banking and fintech
- Healthcare support systems
- Enterprise automation
- Government and public sector platforms
9. How is Gemini 3 Flash priced?
Gemini 3 Flash follows a usage-based pricing model, typically:
- Pay-per-request or per token
- Significantly cheaper than deep reasoning models
- Optimized for high-frequency usage
📌 This pricing structure makes it ideal for:
- Consumer apps
- SaaS platforms
- APIs with millions of daily calls
- Ad-supported and freemium products
10. Can developers monetize products built on Gemini 3 Flash?
Absolutely. Gemini 3 Flash unlocks multiple monetization paths, including:
- Subscription-based AI tools
- AI-powered SaaS platforms
- Chatbots for businesses
- Automation tools for MSMEs
- Edtech and content-creation apps
- Affiliate-driven AI utilities
Its low latency and cost make it easier to build profitable AI products at scale.
11. Is Gemini 3 Flash good for AI agents and workflows?
Yes. Speed-optimized models like Gemini 3 Flash are ideal for AI agents because agents require:
- Fast decision cycles
- Continuous actions
- Real-time feedback loops
Use cases include:
- Autonomous customer support agents
- Sales and CRM agents
- Monitoring and alerting systems
Task-oriented workflow automation
12. What are the main limitations of Gemini 3 Flash?
The primary limitations include:
- Less deep reasoning than heavyweight models
- Potential hallucinations without validation
- Not ideal for complex planning or research
- Requires governance for sensitive use cases
📌 These limitations are manageable with hybrid AI architectures.
13. Will Gemini 3 Flash replace human jobs?
No. Gemini 3 Flash is designed to augment human productivity, not replace humans.
It helps by:
- Automating repetitive tasks
- Speeding up decisions
- Improving customer experience
- Allowing humans to focus on creativity and strategy
Historically, faster technology creates more jobs than it removes, especially in digital economies like India.
14. How does Gemini 3 Flash compare to traditional cloud AI models?
Compared to older cloud AI systems, Gemini 3 Flash offers:
- Lower latency
- Better scalability
- Multimodal intelligence
- Improved cost efficiency
This makes it better suited for modern, real-time internet applications.
15. What is the future of speed-optimized AI like Gemini 3 Flash?
Speed-first AI is the future.
By 2030–2035:
- Most consumer interactions will be AI-mediated
- AI agents will operate continuously in the background
- Speed-optimized models will power 80%+ of AI workloads
- Deep reasoning models will be used selectively
📌 Gemini 3 Flash represents this shift from “AI that thinks” to AI that acts instantly.
Summary
- Speed Is the New Competitive Advantage in AI
In today’s digital economy, users expect instant responses. AI models that can deliver intelligence in milliseconds—not seconds—are becoming the default choice for consumer apps, enterprises, and platforms worldwide. - Gemini 3 Flash Represents a Shift Toward Action-Oriented AI
Instead of focusing solely on deep reasoning, Gemini 3 Flash is designed to act fast—powering real-time chat, search, automation, and AI agents where responsiveness directly impacts user engagement and retention. - Cost-Efficient AI Makes Large-Scale Adoption Possible
By optimizing compute and inference costs, Gemini 3 Flash enables high-volume AI usage without unsustainable infrastructure spending—making AI economically viable for startups, MSMEs, and large enterprises alike. - Perfect Fit for India’s Scale, Mobile-First, and Price-Sensitive Market
With hundreds of millions of smartphone users, growing vernacular demand, and massive real-time digital activity (UPI, e-commerce, edtech), India benefits disproportionately from fast, affordable AI models like Gemini 3 Flash. - Speed-Optimized Models Unlock New Monetization Opportunities
From ad-supported consumer apps and AI-powered SaaS tools to automation platforms and affiliate-driven products, Gemini 3 Flash lowers barriers to building profitable, scalable AI businesses. - The Future Belongs to Hybrid AI Systems, Not One-Size-Fits-All Models
Gemini 3 Flash works best when combined with deeper reasoning, verification layers, and human oversight—creating AI systems that are fast, reliable, ethical, and production-ready.

Conclusion
Gemini 3 Flash is not just another AI model—it represents a fundamental shift in how artificial intelligence is designed, deployed, and experienced. Instead of prioritizing raw intelligence at any cost, Google’s speed-optimized approach recognizes a critical reality of the modern internet: intelligence that arrives late has little value. By delivering near-instant responses at scale, Gemini 3 Flash aligns AI with real-world user behavior, where attention spans are short and expectations are high.
In an era dominated by real-time search, voice assistants, AI agents, and automated decision systems, speed has become a form of power. Gemini 3 Flash transforms AI from a background computation engine into an always-on, responsive layer embedded across apps, platforms, and workflows. For India in particular—where mobile usage, UPI transactions, vernacular demand, and cost sensitivity define the digital ecosystem—fast and efficient AI models are not a luxury, but a necessity for mass adoption.
Looking ahead, the future of AI will not be driven by a single “most intelligent” model, but by smartly orchestrated systems that balance speed, cost, accuracy, and governance. Gemini 3 Flash fits squarely into this future, empowering startups, enterprises, creators, and developers to build AI products that are scalable, monetizable, and user-centric. As AI continues to move from thinking to acting in real time, speed-first intelligence will define the winners—and Gemini 3 Flash is an early glimpse of that next era.
References
To ensure the accuracy, credibility, and authority of this article, the following reliable sources were referenced. These sources cover AI market trends, government policy, enterprise adoption, and India-specific insights.
Primary Sources
- Google AI Blog – Official announcements, research, and product updates on Gemini models and frontier AI.
👉 https://ai.googleblog.com - McKinsey – AI Trends & Insights – Global and India-specific reports on AI adoption, productivity, real-time intelligence, and AI agents.
👉 https://www.mckinsey.com/capabilities/quantumblack/our-insights - Statista – AI Market Data – Verified statistics on global and Indian AI market size, growth rates, and adoption patterns.
👉 https://www.statista.com/technology/ai - NITI Aayog – AI & India GDP – Government policy papers on AI’s impact on India’s economy, Digital Public Infrastructure, and AI adoption strategy.
👉 https://www.niti.gov.in/artificial-intelligence - Economic Times – AI in India – Coverage of AI startups, enterprise adoption, Big Tech investment, and regulatory updates in India.
👉 https://economictimes.indiatimes.com/tech/artificial-intelligence
Additional High-Authority Sources
- World Economic Forum – AI & Future of Work – Research on AI adoption globally, trends, and workforce impact.
👉 https://www.weforum.org/topics/artificial-intelligence - OECD AI Policy Observatory – Global AI governance, ethics, and policy guidelines.
👉 https://oecd.ai - Gartner – AI Infrastructure & Market Trends – Market insights, adoption forecasts, and enterprise AI strategies.
👉 https://www.gartner.com/en/topics/artificial-intelligence - Statista – AI in India – Detailed statistics specific to Indian AI adoption, sectors, and investment.
👉 https://www.statista.com/topics/7011/artificial-intelligence-ai-in-india/ - Times of India – AI News & Trends – Current events and updates on AI deployment in India.
👉 https://timesofindia.indiatimes.com/business/india-business/ai
{kind=link}